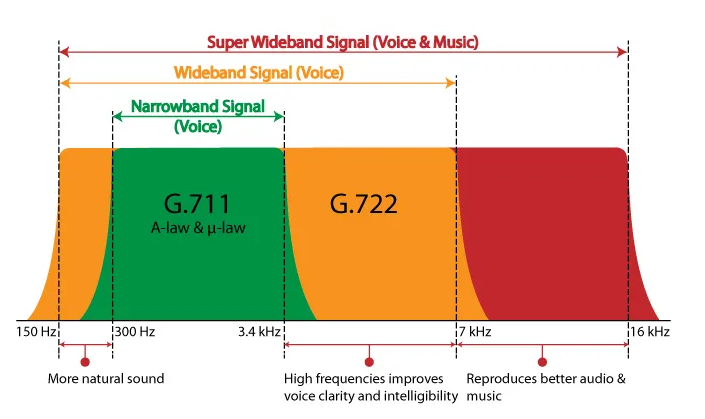
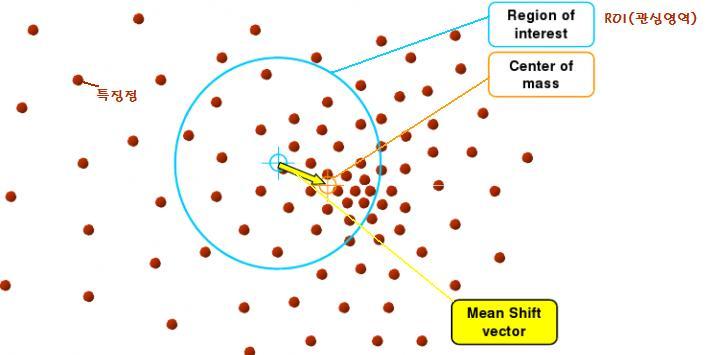
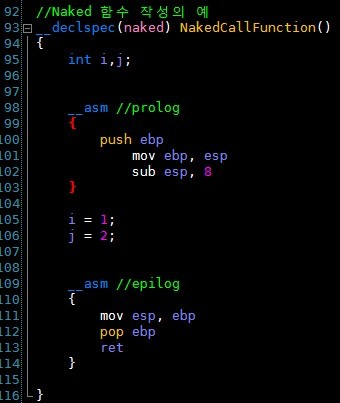
- 윈도우 프로그래밍의 기본1. 윈도우 프로그래밍 모델2. CWnd 클래스3. MFC 코드의 기본 구조4. MFC 코드의 흐름5. 키보드 입력6. 마우스 입력7. GDI 기본8. 비트맵과 이미지 처리9. GDI 고급 - 컨트롤 및 기본 프레임워크10. 메뉴/바로 가기 키/도구 모음/상태 표시줄11. 컨트롤 윈도우의 기본12. 버튼 컨트롤13. 목록 상자와 콤보 상자14. 프로그레스 컨트롤/슬라이더 컨트롤/스핀 컨트롤15. 리스트 컨트롤/트리 컨트롤16. 기타 컨트롤(페이저 컨트롤, 에니메이션 컨트롤, 달력컨트롤, IP 주소 컨트롤, 네트워크 주소 컨트롤, 탭 컨트롤)17. 대화상자 - 고급 사용자 인터페이스18. 깜빡임 방지 (Double Buffering)19. 다중 뷰20. MFC의 구조와 이론21...